
 Biometria
- EDAP
Biometria
- EDAPPara visualizar corretamente configurar a tela para 1024 x 768 pixels
Biometria
- EDAPA distribuição normal
tem como características fundamentais a média
e o desvio
padrão.
Para os interessados por Ciências
Biológicas é a mais importante das distribuições
contínuas pois muitas variáveis
aleatórias
de ocorrência natural ou de processos práticos
obedecem
esta distribuição.
Abraham de Moivre, um
matemático francês exilado na Inglaterra, publicou
a
função densidade de probabilidade da
distribuição
normal com média ![]() e
variância
e
variância ![]() 2
(ou, de forma equivalente, desvio padrão
2
(ou, de forma equivalente, desvio padrão![]() )
em 1733:
)
em 1733:

É importante
lembrar que os
parâmetros populacionais ![]() e
e ![]() possuem
os seguintes significados:
possuem
os seguintes significados:
![]()
![]() =
média populacional: indica a posição
central da
distribuição
=
média populacional: indica a posição
central da
distribuição
![]()
 =
desvio padrão populacional: refere-se à
dispersão
da distribuição
=
desvio padrão populacional: refere-se à
dispersão
da distribuição
Se uma variável
aleatória x tem
distribuição normal com
média ![]() e
variância
e
variância ![]() 2,
diz-se que x ~ N(
2,
diz-se que x ~ N(![]() ,
,![]() 2)
2)
A figura a seguir mostra uma curva normal típica, com seus
parâmetros descritos graficamente.

A curva normal tem forma de
sino, ou seja, é unimodal e
simétrica,
e o seu valor de máxima frequência, a moda
coincide
com o valor da média
e da mediana.
A média
é o centro da curva.
A distribuição de
valores
maiores que a média ( )
e a dos valores menores que a média (
)
e a dos valores menores que a média ( )
é perfeitamente simétrica,
ou seja, se
passarmos uma linha exatamente pelo centro da curva teremos duas
metades, sendo que cada uma delas é a imagem especular da
outra.
)
é perfeitamente simétrica,
ou seja, se
passarmos uma linha exatamente pelo centro da curva teremos duas
metades, sendo que cada uma delas é a imagem especular da
outra.
As extremidades da curva se estendem de forma
indefinida ao longo de sua base (o eixo das abcissas) sem jamais
tocá-la. Portanto, o campo de
variação da
distribuição normal se estende de -
infinito a +
infinito.
Assim sendo, a curva apresenta uma área
central em torno da média, onde se localizam os pontos
de maior frequência e também
possui áreas
menores, progressivamente mais próximas de ambas as
extremidades, em que são encontrados valores muito baixos de
x
(à esquerda) ou escores muito altos (à direita),
ambos
presentes em baixas frequências.
Como em qualquer
função
de densidade de probabilidade a área sob a curva normal
é
1, sendo a frequência
total igual a
100%. Assim, a curva normal é uma
distribuição
que possibilita determinar probabilidades
associadas a todos
os pontos da linha de base.
Portanto, tomando-se quaisquer dois valores pode-se determinar a proporção de área sob a curva entre esses valores. E essa área é o própria frequência da característica que ela determina.
Normal e anormal
A palavra normal tem um significado coloquial bastante indeterminado, mas tem um significado estatístico bem preciso.
O valor de uma variável tem ocorrência
normal quando está entre 95%
da área sob a curva em forma de sino, que tem a
variável
frequência no eixo dos Y, cujas extremidades ocupam 2,5%
cada. Ou seja, um valor é considerado normal se
está na em qualquer ponto entre 0,025 e 0,975 (2,5 e 97,5%)
da área sob a curva.

Portanto,
há dois tipos de "anormal". Todos os valores encontrados na
área que está entre 0 a
2,5% correspondem a um dos tipos. E todos os que estão
no final da curva, ou seja, entre 97,5 e 100% se refiram ao
outro tipo.
Uma pergunta pra pensar: É sempre ruim ser "anormal"?
É muito importante entender como a
curva é afetada pelos valores numéricos de ![]() e
e ![]() .
.
Assim, como se
vê na figura
seguinte, em que x corresponde ao número de
desvios
padrão e Y demonstra a frequência, quanto
maior a
média, mais à direita está a curva.

Note-se
que, se diferentes amostras apresentarem o mesmo valor de
média
![]() e
diferentes valores de desvios padrão
e
diferentes valores de desvios padrão ![]() ,
a distribuição que tiver o maior desvio
padrão
se apresentará mais achatada (c), com maior
dispersão
em torno da média. Aquela que tiver o menor desvio
padrão
apresentará o maior valor de frequência e
acentuada
concentração de indivíduos em valores
próximos
à média (a).
,
a distribuição que tiver o maior desvio
padrão
se apresentará mais achatada (c), com maior
dispersão
em torno da média. Aquela que tiver o menor desvio
padrão
apresentará o maior valor de frequência e
acentuada
concentração de indivíduos em valores
próximos
à média (a).
Já, distribuições
normais com valores de médias diferentes
e o mesmo
valor de desvio padrão possuem a mesma
dispersão,
mas diferem quanto à localização no
eixo dos X. (topo)

A figura anterior mostra
também
que o desvio-padrão controla o grau para o qual a
distribuição
se "espalha" para ambos os lados da curva. Percebe-se que
aproximadamente toda a probabilidade está dentro de
±
3![]() a partir da média.
a partir da média.
Se a variável x tem
distribuição normal, pode ser transformada para
uma
forma padrão, denominada Z, (ou, como
comumente se
diz, pode ser padronizada) subtraindo-se sua média e
dividindo-se pelo seu desvio padrão:
A
equação da curva de z
é:

É importante lembrar que a
área sob a curva pode ser entendida
como uma medida
de sua probabilidade e que a área sob a curva
normal é
igual a 1 (100%).
Assim, a variável x cuja
distribuição é N(![]() ,
,![]() 2)
é transformada na forma padronizada z
cuja
distribuição é N(0,1).
Essa
é a
distribuição normal padrão, que
já está
tabelada, pois os parâmetros da
população
(desvio padrão e média) são conhecidos.
2)
é transformada na forma padronizada z
cuja
distribuição é N(0,1).
Essa
é a
distribuição normal padrão, que
já está
tabelada, pois os parâmetros da
população
(desvio padrão e média) são conhecidos.
Então,
se forem tomados dois valores específicos, pode-se
determinar
a proporção de área sob a curva entre
esses dois
valores.
Para a distribuição Normal, a
proporção
de valores caindo dentro de um, dois, ou três desvios
padrão
da média são:.
|
entre |
é igual a |
|
|
68,26% (1) |
|
|
95,44% (2) |
|
|
99,74% (3) |
Como se chegou a esses valores?
Para responder essa pergunta é necessário conhecer a distribuição de z, que já está tabelada.
Note-se que a Tabela
de z determina a área a
partir do número
de desvios-padrão, os quais são lidos assim:
|
_ , _ _ |
a = número inteiro lido na primeira coluna |
O valor de z será
encontrado na intersecção
entre a coluna e a
linha, sendo adimensional.
Verificando a tabela, percebe-se que para os valores negativos de z as áreas são obtidas por simetria, ou seja, existe o mesmo conjunto de valores, com sinal negativo, para o lado esquerdo da média, pois a tabela é especular.
Os valores de z
permitem delimitar a área sob a curva, pois, como no eixo Y
do gráfico está a frequência
da
variável, a área sob a curva tem o
mesmo valor da
probabilidade de ocorrência daquela
característica.
Exemplo 1
Qual é a área sob a curva normal contida entre z = 0 e z = 1?
Procura-se o valor 1 na primeira
coluna da tabela e o valor da coluna 0,00. O valor da
intersecção
é de 0,3413, ou seja 34,13%.
Entretanto, lembrando que a curva
normal é simétrica, sabe-se
que a área
sob a curva normal contida entre z = 0 e z
= -1
também é 34,13%. Portanto, a
área
referente a -1 < z < 1 vale a soma
de ambas, ou seja,
68,26%.
Recordando
que o valor
central
corresponde a ![]() ,
pode-se traçar o seguinte gráfico, em que se
percebe que, excetuando-se os valores
centrais, sobram apenas 15,87% para cada lado da curva.
,
pode-se traçar o seguinte gráfico, em que se
percebe que, excetuando-se os valores
centrais, sobram apenas 15,87% para cada lado da curva.

Exemplo 2
Assim sendo, considerando a área sob a curva normal, qual é a área correspondente a exatos 95% da curva?
z = 95% = 0, 95
0, 95 / 2 = 0,4750
Procurando esse valor (0,4750) na
tabela de z chega-se a 1,96.
Portanto, como o valor da
área
é o mesmo valor da probabilidade, se uma variável
x tem
distribuição normal, com média ![]() e desvio padrão
e desvio padrão![]() ,
a probabilidade de se sortear da população de
valores
de x um valor contido no intervalo
,
a probabilidade de se sortear da população de
valores
de x um valor contido no intervalo ![]() ±
1,96
±
1,96![]() é igual a 95% ( 47,5% para cada lado da curva ) e a
probabilidade de se sortear da população de
valores de
x um valor não contido no intervalo
é igual a 95% ( 47,5% para cada lado da curva ) e a
probabilidade de se sortear da população de
valores de
x um valor não contido no intervalo ![]() ±
1,96
±
1,96![]() é
igual a 5% ( 2,5% em cada extremo da curva ).
é
igual a 5% ( 2,5% em cada extremo da curva ).

a. O
campo de variação
é menos infinito < x <
mais infinito
b. A
distribuição
normal de x é completamente determinada por dois
parâmetros:
- Média da população = ![]()
- Desvio padrão da população =![]()
c. A distribuição é
simétrica
em relação à média e os
valores de média,
moda e mediana são iguais. A área total sob a
curva é
igual a 1, ou 100%, com exatos 50% dos valores distribuídos
à
esquerda da média e 50% à sua direita
d. A
área sob a curva
normal contida
|
entre |
é igual a |
|
|
: 68,26% (1) |
|
|
: 95,44% (2) |
|
|
: 99,74% (3) |
1. Já
foi visto como se chegou ao valor 68,26%. Como se chegou aos
valores (2) 95,44% e (3) 99,74%?
Tente resolver!
Para ver uma resolução clique aqui.
2. Em uma população de indivíduos adultos de sexo masculino, cuja estatura média é 1,70 m e desvio padrão é 0,08 m, qual é o intervalo de alturas em que 95% da população está compreendido?
Tente resolver!
Para ver uma resolução clique aqui.
3. Na mesma
população, qual a probabilidade de um
indivíduo
apresentar estatura entre 1,60 e 1,82 m?
Tente resolver!
Para ver uma resolução clique aqui.
4. Qual a probabilidade de se encontrar 1 indivíduo com estatura menor que 1,58 m?
Tente resolver!
Para ver uma resolução clique aqui.
5. Sabendo-se
que o índice de massa corpórea em uma
população
de pacientes com diabetes mellitus obedece uma
distribuição
normal e tem média = 27 kg/cm2 e
desvio-padrão
= 3 kg/cm2, qual a probabilidade de um
indivíduo
sorteado nessa população apresentar um
índice
de massa corpórea entre 26 kg/cm2
e a µ?
Tente resolver!
Para ver uma resolução clique aqui.
6. Em mulheres, a quantidade de
hemoglobina por 100 ml de sangue é uma variável
aleatória com distribuição
normal de média ![]() = 16g e desvio
padrão s
= 1g. Calcular a probabilidade de uma mulher apresentar 16 a
18 g por 100 ml de hemoglobina no sangue.
= 16g e desvio
padrão s
= 1g. Calcular a probabilidade de uma mulher apresentar 16 a
18 g por 100 ml de hemoglobina no sangue.
Tente resolver!
Para ver uma resolução clique aqui.
(topo)
Se for retirado um certo número de amostras aleatórias de mesmo tamanho de uma população, não se deve esperar que todas as médias e desvios padrões amostrais sejam iguais. Encontra-se uma distribuição das médias amostrais.
|
População |
|||
|
Amostra 1 |
Amostra 2 |
Amostra 3 |
Amostra 4 |
|
|
|
|
|
|
s1 |
s2 |
s3 |
s4 |
Intuitivamente percebe-se que o
centro desta distribuição está
próximo da
média real da população.
Exemplo: Supondo
as seguintes frequências cardíacas em 5
amostras,
cada qual com 3 indivíduos, de uma
população:
|
Amostras |
1 |
2 |
3 |
4 |
5 |
|
Dados |
68, 68, 71 |
68, 70, 72 |
67, 70, 73 |
67, 69, 69 |
68, 69, 70 |
|
Média ( |
69,00 |
70,00 |
70,00 |
68,33 |
69,00 |
A média das médias é igual a:
![]() = ( 69,00 + 70,00 + 70,00 + 68,33 + 69,00) / 5 = 69,27
= ( 69,00 + 70,00 + 70,00 + 68,33 + 69,00) / 5 = 69,27
Depois, calcula-se uma medida da
dispersão das cinco médias amostrais: o desvio
padrão das médias.
Ressalte-se que, nesse caso, ![]() a
= cada média amostral,
a
= cada média amostral, ![]() = média das amostras (69,27) e n = número de
amostras.
= média das amostras (69,27) e n = número de
amostras.
Substituindo os valores na
equação:
Desvio padrão = raiz [(69,00 - 69,27)2 + (70,00 - 69,27)2 + … + (69,00 - 69,27)2 ] / 4 = 0,71
Notar que nenhuma das médias
equivale ao valor encontrado. Assim, sempre se comete erro
ao se calcular a média.
O procedimento descrito acima é
um método empírico para
definição do erro
padrão da Média (EPM).
Matematicamente é possível calcular esse erro. O erro da média ou erro padrão da amostra ou, simplesmente erro padrão (sx ou EPM) é dado por:
/
raiz n ou sx
= s / raiz n,em que:
s = Desvio
padrão da amostra
(o desvio padrão da população
não é
conhecido)
=
Desvio padrão da população
n = Tamanho da
amostra
Conclui-se que:
![]() Existe
uma relação inversa entre o
tamanho
da amostra e o erro padrão,
ou seja, quando o
tamanho da
amostra aumenta o erro padrão diminui.
Existe
uma relação inversa entre o
tamanho
da amostra e o erro padrão,
ou seja, quando o
tamanho da
amostra aumenta o erro padrão diminui.
![]() O
erro padrão da média diminui com a raiz quadrada
do
número n de medições realizadas.
Portanto,
realizar mais medidas melhora a determinação do
valor
médio como estimador da grandeza que se deseja
conhecer. (topo)
O
erro padrão da média diminui com a raiz quadrada
do
número n de medições realizadas.
Portanto,
realizar mais medidas melhora a determinação do
valor
médio como estimador da grandeza que se deseja
conhecer. (topo)
Nesse caso, os parâmetros da população (desvio padrão e média) são conhecidos.
Exemplo:
Um médico receitou um
medicamento vasodilatador (Nifedipina) para Hipertensão
Arterial, mas ele suspeita que o medicamento está aumentando
a
frequência cardíaca dos
pacientes.
Sabedor que a
população
apresenta os seguintes valores: ![]() = 69,8; s = 1,86, coletou uma
amostra aleatória
de 50 pacientes e mediu as suas frequências
cardíacas,
obtendo a média de 70,5. A suspeita se
confirmou?
= 69,8; s = 1,86, coletou uma
amostra aleatória
de 50 pacientes e mediu as suas frequências
cardíacas,
obtendo a média de 70,5. A suspeita se
confirmou?
Estabelece-se as hipóteses, com alfa = 5%:


Calcula-se o erro da média:
sx
=![]() /
raiz n = 1,86 / raiz 50
= 1,86 / 7,0710 =
0,2630
/
raiz n = 1,86 / raiz 50
= 1,86 / 7,0710 =
0,2630
Calcula-se z:
z = (![]() -
- ![]() )
/ sx
= (69,8 - 70,5) / 0,2630 = -0,7 / 0,2630 = -2,66
)
/ sx
= (69,8 - 70,5) / 0,2630 = -0,7 / 0,2630 = -2,66
Consultando o valor -2,66 na
Tabela de z
obtém-se
o valor 0,4961.
Portanto: z = 0,50 - 0,4961 = -0,0039 = 0,39%
 |
Ou seja, existe uma
probabilidade de rejeita-se H0 e aceita-se H1, concluindo-se que a suspeita do médico se confirmou e a nifedipina aumentou significativamente a frequência cardíaca. |
Em 1908, o
estatístico inglês
William Sealey Gosset, que assinava os seus trabalhos com o
pseudônimo de "Student" descobriu essa
distribuição.
Mas seus trabalhos foram ignorados e redescobertos por
Fisher só em 1924-25, apesar de terem enorme
importância
estatística.
O valor de t é a medida do
desvio entre a média amostral ![]() ,
estimada a partir de uma amostra aleatória de tamanho n, e a
média
,
estimada a partir de uma amostra aleatória de tamanho n, e a
média ![]() da população, usando o erro da média
como
unidade de medida:
da população, usando o erro da média
como
unidade de medida:
O parâmetro
usado para
descrever a distribuição t é
o número
de graus de liberdade que terá
relação
com o tamanho da amostra (n) .
Os dados sobre t
também já se encontram tabelados. (Para ver a
tabela de t, clique aqui).
A
tabela é lida como a de Qui quadrado, ou seja, probabilidade
(P) nas colunas e Graus de liberdade (G.L.) nas linhas, sendo o valor
de tc (t
crítico) encontrado na
intersecção entre a coluna
de 5% e a linha
correspondente ao número de graus de liberdade da amostra,
sendo G.L. = n - 1.
Do mesmo modo que a tabela de z,
a tabela de t é especular, ou seja,
para os valores
negativos de t existe esse mesmo conjunto de
valores, mas
com sinal negativo. Ou seja, a tabela de t
é
bicaudal. (topo)
Uma das
aplicações
importantes do conhecimento da distribuição de t
é a possibilidade de, conhecendo-se
- a média
amostral de uma variável x e
- o erro da média = sx
= s / raiz n
poder estimar quais valores x poderá
assumir dentro de um intervalo em torno da média ![]() .
.
Esse
intervalo é denominado "Intervalo de confiança da
média ![]() "
e os valores que o delimitam são os "limites fiduciais"
ou "limites de confiança da média".
"
e os valores que o delimitam são os "limites fiduciais"
ou "limites de confiança da média".
Supondo
uma variável x, com distribuição
normal, cuja
média populacional ![]() não
conhecemos e que, numa amostra casual de tamanho n, já
se calculou x médio (
não
conhecemos e que, numa amostra casual de tamanho n, já
se calculou x médio ( ![]() ) e o
erro da média (sx).
) e o
erro da média (sx).
Se quisermos
estabelecer o intervalo de confiança da média ![]() ,
com probabilidade de 95%, devemos verificar primeiramente, em uma
tabela de t, qual é o valor de t,
com n-1
graus de liberdade e 5% de probabilidade. Esse valor é
chamado
de t crítico (tc).
,
com probabilidade de 95%, devemos verificar primeiramente, em uma
tabela de t, qual é o valor de t,
com n-1
graus de liberdade e 5% de probabilidade. Esse valor é
chamado
de t crítico (tc).
É
importante lembrar que o valor de t
amostral t
= ( ![]() -
- ![]() )
/ sx deve estar no intervalo entre - tc
e + tcem
95% das
amostras.
)
/ sx deve estar no intervalo entre - tc
e + tcem
95% das
amostras.
Portanto, pode-se dizer que existe uma probabilidade
de 95% de encontrar:
|
- tc < |
( |
< + tc |
Se multiplicarmos todos os termos
da expressão por sx :
|
- tc.sx < |
( |
< + tc.sx |
Se transpusermos ![]() :
:
|
- |
|
<
- |
Mudando os sinais:
|
|
|
> |
Invertendo os termos:
|
|
|
< |
Essa última expressão
indica que antes de se tomar uma amostra para
estudo, existe
uma possibilidade de 95% do intervalo ![]() ± ( tc sx )
conter a média
± ( tc sx )
conter a média
![]() .
.
Exemplo:
1. Foi tomada a distância inter-pupilar de 131 mulheres
adultas e obteve-se ![]() = 59,2 mm e s = 2,75mm
= 59,2 mm e s = 2,75mm
sx
= s / raizn n =
2,75 / raiz 131 = 0,2402 mm
Para estimar o intervalo de
confiança de 95% da média da
distribuição
da distância inter-pupilar nessa amostra, consulta-se a
tabela
de t com com n -1 graus de liberdade (131 - 1 =
130) e 5% de
probabilidade.
Como 130 >120 (último
valor na coluna 1) pode-se ler o valor de t crítico na linha
referente a "infinito" e na coluna de 0,05.
|
|
|
< |
59,2 - ( 1,96 x 0,2402) <
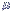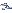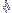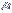 <
59,2 + ( 1,96 x 0,2402), obtendo-se:
<
59,2 + ( 1,96 x 0,2402), obtendo-se:
|
58,73 mm < |
|
< 59,67mm |
ou seja, a média populacional,
calculada a partir de uma única amostra, deve estar entre os
limites fiduciais 58,73 e 59,67
mm, um espaço menor que 1 mm (0,94 mm).
2. Suponha que os dados são os mesmos, exceto
o tamanho amostral.
a. Qual seria o intervalo fiducial se n fosse
231? b. 61?
c. 31? d. 21? e. 11?
f. 6?
|
n = |
231 |
131 |
61 |
31 |
21 |
11 |
6 |
|
média = |
59,2 |
59,2 |
59,2 |
59,2 |
59,2 |
59,2 |
59,2 |
|
s = |
2,75 |
2,75 |
2,75 |
2,75 |
2,75 |
2,75 |
2,75 |
|
tc = |
1,960 |
1,960 |
2,000 |
2,042 |
2,086 |
2,228 |
2,571 |
|
sx = s / raiz n |
0,1809 |
0,2403 |
0,3521 |
0,4939 |
0,6001 |
0,8292 |
1,1227 |
|
tc.sx = |
0,3546 |
0,4709 |
0,7042 |
1,0086 |
1,2518 |
1,8474 |
2,8864 |
|
M-( tc.sx) = |
58,85 |
58,73 |
58,50 |
58,19 |
57,95 |
57,35 |
56,31 |
|
M-( tc.sx) = |
59,55 |
59,67 |
59,90 |
60,21 |
60,45 |
61,05 |
62,09 |
|
intervalo fiducial = |
0,71 |
0,94 |
1,41 |
2,02 |
2,50 |
3,69 |
5,77 |
Os dados biológicos muitas vezes apresentam-se graficamente como curvas com distribuição normal ou binomial.
É importante notar que a distribuição binomial se aproxima da distribuição normal à medida que o número de experimentos aumenta. E deve-se notar que curvas que obedecem binomiais, especialmente após GL = 30, são extremamente semelhantes às normais.
Assim, quando uma amostra tem n > 30 uma curva binomial tende a se assemelhar a uma curva normal. No caso de n = 31 a distribuição (p + q)31 terá os seguintes valores:
|
Se p = q = 0,5 |
Se p = 0,75 e q = 0,25 |
|
|
|
|
95% da
distribuição
está entre |
95% da
distribuição
está entre |
Quando uma amostra tem n > 30,
uma das consequências da
aproximação da
curva binomial à normal é que a média
e o desvio
padrão da distribuição binomial podem
ser usados
para por à prova:
|
H. Nula: a
proporção observada (o) de 1
entre 2 acontecimentos alternativos não se desvia
significativamente da proporção
teórica esperada ( |
|
|
H. Alternativa: o
desvia-se significativamente de |
|
Nesse caso, z = ( o
- ![]() )
/ o
)
/ o
valor de z é comparado com o valor de tc:

Exemplo 1.
Um ortopedista ao
estudar 52 filhos de casais que incluem 1 cônjuge com uma
anomalia óssea verificou que 20 dos filhos apresentam a
mesma
anomalia encontrada em 1 de seus pais.
Hipótese Nula
(H0): é uma herança
dominante, autossômica
e monogênica, ou seja, p = q = 0,5
O número
esperado de anômalos é ![]() = nq = 52 x 0,5 = 26
= nq = 52 x 0,5 = 26
O desvio padrão é s = raiz
n.p.q = raiz 52
x 0,5 x 05 = 3,606
O
número observado de anômalos é = 20
z
= (20 - 26) / 3,606 = -1,664
gl = 52 -1 = 51, tc =
2,00
____________ -tc __________________+ tc
__________ -2,00 __|_____ 0 _______+2,00___________
_______________-1,664
Como -tc
< z < +
tc
aceita-se
H0.
Exemplo 2
E se o
ortopedista tivesse encontrado não 20, mas apenas 17 filhos
com a
mesma anomalia dos pais?
z = (17 - 26) / 3,606 = -2,496
Se apenas 17 filhos fossem anômalos, como z > tc poder-se-ia rejeitar H0.
____________ -tc ______________________+ tc
_____!_____ -2,00 __|___ 0 ______+2,00___________
___-2,496
Como z < -tc
pode-se rejeitar
H0.
Mesmo em amostras com n
bem menor
que 30 indivíduos pode-se usar métodos
aplicáveis
à distribuição normal.
Exemplo 1:
Considerando uma certa anomalia que tem probabilidade de 0,5 de se
manifestar em filhos de casais que incluem 1 cônjuge afetado.
Analisando irmandades de diferentes tamanhos geradas por esses
casais, qual a probabilidade de encontrarmos pelo menos 7
anômalos
nas irmandades com 12 irmãos?
Resolução
1
 Usando o Triângulo
de Pascal
Usando o Triângulo
de Pascal
Para se determinar os coeficientes da equação,
monta-se o Triângulo até atingir o expoente
desejado no
binômio de Newton:
|
Coeficientes |
Expoente |
|
1 |
0 |
Portanto, a equação
será:
1p12 q0 + 12 p11 q1 + 66p10q2 + 220p9 q3 + 495p8 q4 + 792p7 q5 + 924p6 q6 + 792p5 q7 + 495 p4 q8 + 220p3q9 + 66p2 q10 + 12p1 q11 + 1p0 q12
Sendo p = normalidade e q
= anomalia,
como o problema pede "pelo menos 7 anômalos nas irmandades
com 12 irmãos" nos interessa apenas essa parte da
equação:
792p5 q7 + 495 p4 q8 + 220p3q9 + 66p2 q10 + 12p1 q11 + 1p0 q12
Somando-se seus
coeficientes (792 +
495 + 220 + 66 + 12 + 1= 1586), temos 1586 indivíduos para
4096 no total das irmandades.
1586 / 4096 = 0,3872, portanto,
P = 38,7%
Ou seja, a probabilidade
de se
encontrar "pelo menos 7 anômalos nas irmandades com 12
irmãos" é igual a 38,72%.
Resolução
2
Usando as
características
da curva normal
![]() =
nq = 12 . 0,5 = 6
=
nq = 12 . 0,5 = 6
s = raiz npq = raiz
12 . 0,5 . 0,5 = 1,73
O valor da
média pode ser
tomado como um centro de classe do intervalo 5,5 a 6,5.
z = (x
- ![]() ) / (
) / (![]() )
= (6,5 - 6) / 1,73 = 0,29
)
= (6,5 - 6) / 1,73 = 0,29
Consultando a tabela de z,
vê-se que o valor correspondente a 0,29 é 0,1141,
o que
indica que a área ocupada a partir de 5,5 é
0,5000 -
0,1141 = 0,3869, ou seja, que tem uma probabilidade de 38,7%.
Portanto, nota-se que
apesar de
estarmos tratando de outra distribuição
(binomial) as
fórmulas referentes à
distribuição normal
podem ser usadas pois a diferença encontrada nos resultados
é
insignificante, (38,72% e 38,69%) é insignificante,
praticamente desprezível.
Exemplo 2:
Qual a probabilidade de
encontrarmos
irmandades com 4 indivíduos normais e 8 anômalos?
Resolução 1
Usando o Triângulo
de Pascal
Verificar no triângulo montado. O valor
desejado é 495 p4q8.
Substituindo p e q
por 0,5:
495 0,54 0,58 = 0,121
ou 12,1%
Resolução 2
Usando as
características
da curva normal
A área sob a
curva na classe
correspondente a 8 (com limites 7,5 e 8,5) deve ser calculada,
lembrando que z = ( x
- )
/
s:
z1
= (limite min
- )
/
e z2 =
(limite max -
)
/
z1 = 7,5 - 6 / 1,73 = 0,87
e z2
= 8,5 - 6 / 1,73 = 1,45
Verificando na Tabela
de z:
0,87 corresponde a 0,3078 e 1,45 corresponde a 0,4265
A diferença
entre essas
áreas determina uma área limitada por 0,87 e
1,45, ou
seja,
0,4265 - 0,3078 = 0,1187 = 0,119
0,119 =
aproximadamente 12%
Novamente percebe-se que
apesar
de ser um caso de distribuição (binomial) as
fórmulas
referentes à distribuição normal podem
ser
usadas pois a diferença encontrada nos resultados
é
insignificante, praticamente desprezível. (topo)
Em uma amostragem
não probabilística, o
tamanho amostral é
estabelecido sem nenhuma base de sustentação
técnica.
Comumente corresponde a 10% ou 15% da população
alvo.
Já, em uma amostragem
probabilística, o tamanho da amostra é
função:
![]() do(s)
parâmetro(s) a estimar,
do(s)
parâmetro(s) a estimar,
![]() do
nível de confiança desejável,
do
nível de confiança desejável,
![]() do
erro tolerável ou índice de
precisão
escolhidos,
do
erro tolerável ou índice de
precisão
escolhidos,
![]() do
grau de dispersão da população,
do
grau de dispersão da população,
![]() pode,
ainda, depender do tamanho da população e de
outros parâmetros específicos.
pode,
ainda, depender do tamanho da população e de
outros parâmetros específicos.
Basicamente, o tamanho da
amostra
depende da precisão desejada, conforme
o arbítrio
do pesquisador. Assim, é intuitivo perceber que o
tamanho depende do erro aleatório mencionado acima.
Há
uma relação inversa entre o erro e o tamanho da
amostra. Amostras “grandes” estão
associadas a
erros “pequenos” e amostras
“pequenas” a
erros “grandes”. Assim, deve-se procurar uma
compatibilidade entre o tamanho amostral e o erro que se
“tolera” cometer em um estudo.
Se soubermos
o valor do desvio padrão da variável que
está
sendo estudada podemos ter uma ideia de qual deve ser um bom
tamanho amostral, pois
em que n = tamanho amostral.
O erro tolerável (E) é :
Elevando ao quadrado, obtém-se:
o que permite escrever:
Exemplo 1:
Foi feita uma dosagem
bioquímica
de um certo composto em uma amostra de 36 indivíduos e
obteve-se ![]() =
300
mg e s = 15 mg. Qual é um bom tamanho para essa amostra
(n)?
=
300
mg e s = 15 mg. Qual é um bom tamanho para essa amostra
(n)?
Aceitando-se que s
é um
bom estimador para![]() :
:
s = 15 mg e sx=
![]() /
raiz n = 15 /
raiz 36 =
2,5 mg
/
raiz n = 15 /
raiz 36 =
2,5 mg
E = 1,96 s = 1,96 x 2,5 = 4,9 mg = precisão da
estimativa
Ou seja, a
média tem 95%
de chance de estar entre 300 ± 4,96 (entre 295,1 e 304,9 mg).
Entretanto, se o
pesquisador
quiser aumentar essa precisão de modo
que o intervalo
de confiança da média fique entre 298 e 302, E
será
igual a 2.
Então:
n = 1,962.![]() 2
/ E2 = 1,962 .152
/ 22 =
216,09 = 216 indivíduos
2
/ E2 = 1,962 .152
/ 22 =
216,09 = 216 indivíduos
Como já há 36 pessoas na amostra, faltam 216 - 36 = 180
Assim, para conseguir que
o erro
passe de 4,9 para 2 o pesquisador precisaria de mais 180
indivíduos.
Obs. Se a distribuição da amostra for binomial (e não normal ) deve-se usar essas fórmulas:
E = 1,96 raiz pq
/ n e n =
1,962 pq / E2
(topo)
Momentos
|
1o. momento |
2o. momento |
3o. momento |
4o. momento |
|
r = 1 |
r = 2 |
r = 3 |
r = 4 |
|
|
|
|
|
Momentos centrados na média
|
1o. momento |
2o. momento |
3o. momento |
4o. momento |
|
m1 |
m2 |
m3 |
m4 |
|
|
|
|
|
Em relação ao
primeiro momento, sabe-se que é nulo, pois, ![]() (x
-
(x
- ![]() )
= 0
)
= 0
O segundo momento ( ![]() (x -
(x - ![]() )2
/ n ) é muito parecido com a variância (
)2
/ n ) é muito parecido com a variância (
![]() (x
-
(x
- ![]() )2
/ n-1 )
)2
/ n-1 )
Fórmulas para dados individuais:
m2
=
![]() x2
/ n -
x2
/ n - ![]() 2
2
m3
=
x3 / n - (3.![]() .
.
![]() x2)
/ n + 2
x2)
/ n + 2![]() 3
3
m4
=
![]() x4
/ n - (4.
x4
/ n - (4.![]() .
.
![]() x3)
/ n + (6
x3)
/ n + (6![]() 2
2
![]() x2)
/ n - 3
x2)
/ n - 3![]() 4
4
Fórmulas para dados
agrupados em classes:
![]() = média
= média
i = intervalo de classe
X =
centros de classe
f = frequência absoluta
n
= tamanho da amostra
chega-se a essas fórmulas:
m2
=
{![]() (f
X2)/n - [(
(f
X2)/n - [(![]() f
X)2 / n2] } i2
f
X)2 / n2] } i2
m3
=
{ ![]() (f
X3)/n - (3.
(f
X3)/n - (3.![]() f
X .
f
X .![]() f
X2)/n2 ) + [ 2.(
f
X2)/n2 ) + [ 2.(![]() f
X)3
/n3]
} i3
f
X)3
/n3]
} i3
m4
=
{ ![]() (f
X4)/n - [(4.
(f
X4)/n - [(4.![]() f
X.
f
X.![]() f
X3)/n2]
+ [ 6.(
f
X3)/n2]
+ [ 6.(![]() f
X)2.(
f
X)2.(![]() f
X2)/n3] - [3 (
f
X2)/n3] - [3 (![]() f
X)4/n4] } i 4
(topo)
f
X)4/n4] } i 4
(topo)
O terceiro momento
centrado na média
é utilizado na investigação de assimetria
nas distribuições. Nas
distribuições
unimodais essa investigação é muito
interessante
pois é necessário saber se existe assimetria
positiva
ou negativa, ou seja, se é significativo o alongamento de
uma
das caudas da distribuição (à direita
ou à
esquerda da média).
|
Assimetria Negativa: M < Mi < Mo |
Assimetria Positiva: Mo > Mi > M |
|
|
|
Para estudar a assimetria
em distribuições unimodais Fisher
propôs o
coeficiente g1
|
coeficiente |
quantidade k |
|
|
g1 = k3 / s3 |
k3 = m3 n2 / (n-1).(n-2) |
|
|
sendo que: |
|
|
|
erro do coeficiente |
teste t |
|
|
sg1 = raiz [(6n (n-1) / (n-2) (n+1)(n+3)] |
t = g1 / sg1 |
|
|
|
|
|
|
coeficiente |
quantidade k |
erro do coeficiente |
|
g1 = m3 / m2 raiz m2 |
k3 ~ m3 |
sg1 = raiz 6/n |
Para verificar se o valor de g1
se desvia significativamente de zero calcula-se
a razão
entre g1
e sg1
obtendo-se um t que deve ser comparado a um t crítico (tc)
com infinitos graus de liberdade ao nível de
significância
de 5% ( tc
= ± 1,96).
Um valor de t calculado igual ou maior que +1,960 indica que g1 é significativamente maior que zero, ou seja, que a assimetria é positiva. Do mesmo modo, um valor de t calculado igual ou menor que -1,960 indica que g1 é significativamente menor que zero, ou seja, que a assimetria é negativa.
O quarto momento centrado na média é utilizado na investigação de curtose nas distribuições. Calcula-se:
|
coeficiente |
quantidade k |
|
|
g2 = k4 / (s2)2 |
k4 = [m4 n2 (n+1) - 3(n-1)3 (s2)2] / [(n-1).(n-2) (n-3)] |
|
|
sendo que: |
|
|
|
|
|
|
|
sg2 = raiz[( 24n (n-1)2 / (n-3)(n-2) (n+3)(n+5)] |
t = g2 / sg2 |
|
|
|
||
|
coeficiente |
quantidade k |
erro do coeficiente |
|
g2 = m4 / (m2)2 - 3 |
k4 = m4 - 3 (m2)2 |
sg2 = raiz 24/n |
O teste t tem tc
= ± 1,96, sendo que um valor de t
calculado igual ou
maior que +1,960 indica que g2
é
significativamente maior que zero, ou seja, que a
distribuição
é leptocúrtica. Do mesmo modo, um valor de t
calculado igual ou menor que -1,960 indica que g2
é significativamente menor que zero, ou seja, que a
distribuição é platicúrtica.
|
Para facilitar os
cálculos utilize uma planilha especial: |
Como já foi
visto, o
coeficiente
de variação
é uma medida da dispersão dos dados.
E é
a razão entre o desvio padrão e a
média
amostral:
Quando se transforma o desvio
padrão em uma fração da
média pode-se
comparar amostras com desvios-padrão diferentes.
O
teste t é feito, por meio da seguinte
fórmula:
em que:
VCa =
Variância da amostra a e VCb =
Variância da amostra b
Graus de liberdade = na + nb
- 4,
em que na e nb
são os tamanhos
amostrais.
Se os coeficientes de variação forem menores que 0,30 (o que acontece quase sempre) pode-se calcular a variância do seguinte modo:
Se os coeficientes de variação forem maiores que 0,30, calcula-se a variância assim:
em que
m2,
m3 e m4
= segundo, terceiro e quarto momentos centrados na
média
![]() =
média
=
média
n = tamanho da amostra
Exemplo:
Supondo 2
amostras onde foi coletada a altura de indivíduos. Ambas
são constituídas por
indivíduos caucasóides, de sexo
masculino, de
Campinas. Mas a primeira amostra recém nascidos e a
segunda universitários, sendo que:
Amostra a. recém-nascidos, caucasóides, sexo masculino, de Campinas, em que:
![]() = 49,0; s = 2,55, n = 50
= 49,0; s = 2,55, n = 50
Amostra b.
universitários, caucasóides, sexo masculino, de
Campinas, em que:
![]() = 170,11; s = 8,38, n = 100
= 170,11; s = 8,38, n = 100
Há uma maneira de conseguir desenhar a curva normal esperada para a população a partir dos dados amostrais.
Exemplo:
Ao estudar o
nível de uma certa enzima nos hemolisados de 138 homens
brasileiros adultos, jovens e sadios, verificou-se que a sua
distribuição segundo a atividade dessa enzima era
unimodal. Os dados amostrais a respeito dessa atividade (x 104)
foram agrupados na tabela abaixo.
Com base nesses dados, criar um
gráfico, em colunas, da distribuição
observada,
sob um gráfico, em linha, de
sua curva normal.
|
min |
max |
cen |
f |
min |
max |
cen |
f |
|
18,00 |
22,00 |
20 |
0 |
58,00 |
62,00 |
60 |
15 |
|
22,00 |
26,00 |
24 |
2 |
62,00 |
66,00 |
64 |
9 |
|
26,00 |
30,00 |
28 |
1 |
66,00 |
70,00 |
68 |
8 |
|
30,00 |
34,00 |
32 |
3 |
70,00 |
74,00 |
72 |
7 |
|
34,00 |
38,00 |
36 |
8 |
74,00 |
78,00 |
76 |
3 |
|
38,00 |
42,00 |
40 |
11 |
78,00 |
82,00 |
80 |
1 |
|
42,00 |
46,00 |
44 |
14 |
82,00 |
86,00 |
84 |
2 |
|
46,00 |
50,00 |
48 |
15 |
86,00 |
90,00 |
88 |
0 |
|
50,00 |
54,00 |
52 |
20 |
90,00 |
94,00 |
92 |
0 |
|
54,00 |
58,00 |
56 |
18 |
94,00 |
98,00 |
96 |
1 |
Segue, abaixo, um método
fácil para desenhar a curva normal:
a.
Calcular a média amostral (
![]() )
)
b.
Calcular o desvio padrão amostral
(s)
c. Obter os pontos para a curva normal completando
a tabela a seguir,
usando uma tabela com a distribuição
de Y.
d. Traçar um gráfico em colunas da distribuição
e. Sobrepor ao gráfico a curva normal
Os valores obtidos na última coluna devem ser usados para montar o gráfico.
|
Lim. min. |
Lim max |
Centro |
x - |
z = (x - |
y |
y.n/s |
100. [ (yn)/s] / |
|
. |
. |
. |
. |
. |
. |
||
|
. |
. |
. |
. |
. |
. |
||
|
… |
. |
. |
. |
. |
. |
. |
Qual é o tipo
do gráfico a ser criado?
|
Para facilitar os
cálculos utilize uma planilha especial: |

|
Copie
esse texto em formato
pdf Depois, clique em"Salvar destino como" (ou algo semelhante ) Escolha o local onde salvar e clique em OK. |
|



Este "site", destinado prioritariamente
aos alunos de Fátima Conti,
está disponível sob FDL (Free
Documentation Licence),
pretende auxiliar quem se interessa por Bioestatística,
estando em permanente
construção.
Sugestões e
comentários
são bem vindos.
Se desejar colaborar
clique
aqui.
Agradeço
antecipadamente.
Deseja enviar essa página?
Se você usa um
programa
de correio eletrônico devidamente configurado para
um e-mail
pop3, clique em "Enviar página" (abaixo) para
abrir o programa.
Preencha o endereço
do destinatário da mensagem.
E pode acrescentar o que quiser.
(Se não der certo,
clique aqui
para saber mais).




